


I read Principles of building AI Agents a couple of months back, but only got the paper copy few weeks ago. I’ve been carrying it around quite a bit — mostly to get a better picture of it as others have already shared theirs.
What was interesting to me was using primitives as the foundation of building agents. When we started building agents ( early 2024) there was very little material around it. With IndieGrow we even built a “deep research” tool before it was “cool” or there was much literature around it though now almost every lab an middleware company has a variation of a deep agent.
Anyhow, I highly recommend the read; I was originally planning to share just my reading notes but realized I had a few pages of highlights, so I did a proper write up including our experiences so far.
The book doesn’t have a table of contents but I figured it would be useful to share one:
And I added also:
Zero-shot: The “YOLO” approach. Ask the question and hope for the best. Single-shot: Ask a question, then provide one example (w/ input + output) to guide the model Few-shot: Give multiple examples for more precise control over the output.
We actually built a prompt CMS into Mastra’s local development environment for this reason.
CAPITALIZATION can add weight to certain words. XML-like structure can help models follow instructions more precisely. Claude & GPT-4 respond better to structured prompts (e.g., task, context, constraints).
We have seen this first-hand. When we started at HYPD, we were testing the models with “offline” datasets against both ChatGPT and Claude — trying to see how far we could push pure LLM performance before adding prompts. We realized early on that prompt versioning and structure werethe key to getting the desired output. It’s the most fundamental primitive, and honestly, I didn’t understand how deep it goes until I listened to Andrej Karpathy on the Dwarkesh podcast*.
Even now, a lot of our time is spent breaking prompts apart — looking at structure, words, testing small differences, and seeing how they affect outputs.
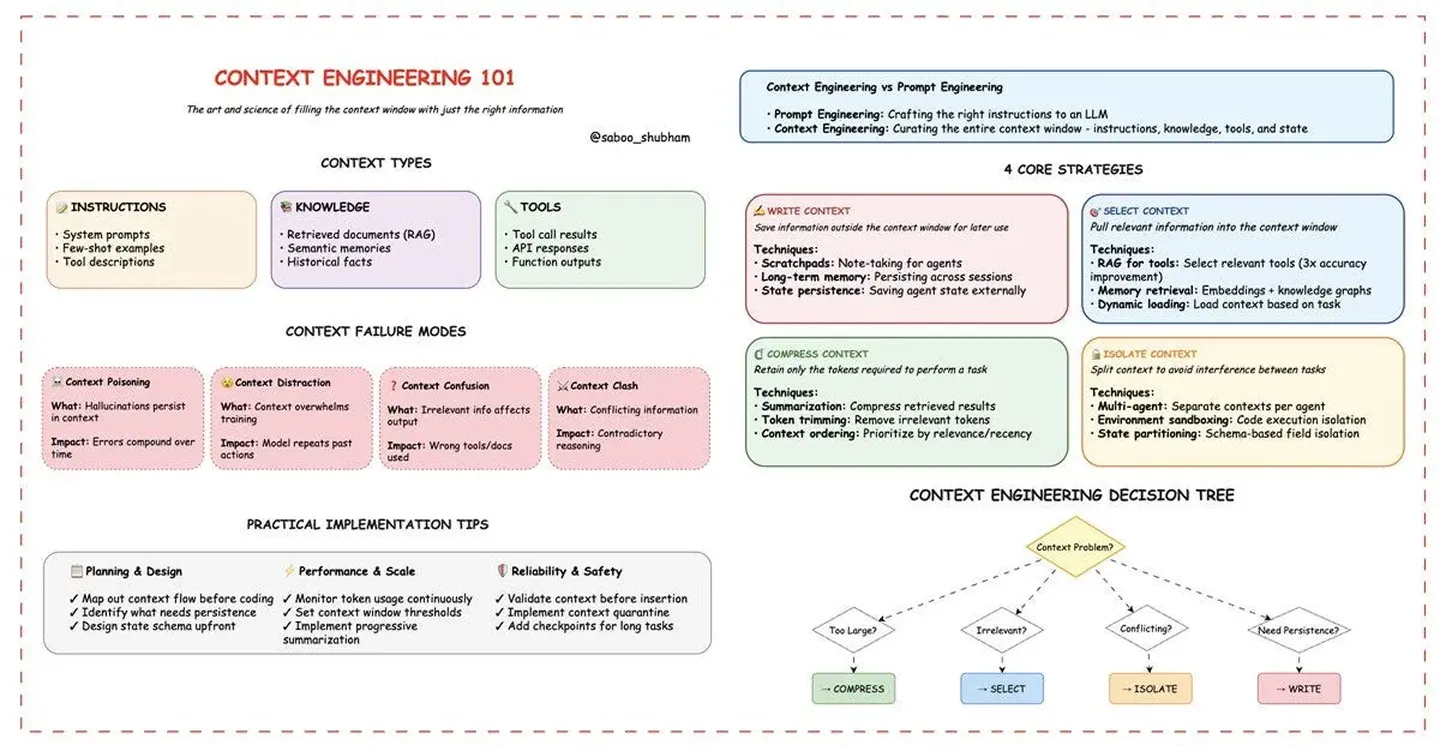
More interestingly now this “discipline” evolved intoContext Engineeringas it includes more individual components like tool descriptions, examples, message history, memory, RAG and other pieces of content and context that are made available to the model.
In practice, because LLMs are “stateless” you either build the context around the agent or use various frameworks (like Mastra or Langgraph) to help handle this.
Most models support “structured output” to enable this.
Use semantic naming that matches the tool’s function (eg multiplyNumbers instead of doStuff)
semanticRecall indicates that we’ll be using RAG (more later) to search through past conversations. topK is the number of messages to retrieve. messageRange is the range on each side of the match to include.
In terms of structured outputs it was an interesting development (returns “deterministic” json or similar format). We do use that across a couple of our agents — from the intent classifier to the SQL generator or for error message generation. OpenAI pioneered it and made it quite reliable. I think this is even more useful for agent “actions”.
Before tool use, there’s a question about how we define agents and the current mainstream definition* is:
an LLM plus tool(s) with a goal, running in a loop to complete that task
We use different tools like SQL/GAQL generation, or rendering charts. Originally the tools were paired individually with the agents and we trace when they are used.
In terms of semantic naming — I think this one speaks for itself. I don’t know if we need to use it, but in general semantic names are easier for models, easier for humans to read or for DeepWiki* to connect the dots.
In terms of RAG (Retreival Augmented Generation), this is a slightly more complex topic and is covered a bit later. High level — it fits into the broaderContext Engineeringprimitive with all its components. You can do RAG across many of the steps. But for example for messages and message history — we provide full context. While for memory/personalization it might make sense to not load everything in the memory but just the relevant parts.
You could have one LLM call check for 12 symptoms. But that’s a lot to ask. Better to have 12 parallel LLM calls, each checking for one symptom.
Sometimes, you’ll want to fetch data from a remote source before you feed it into an LLM, or feed the results of one LLM call into another. In Mastra, you chain with the .then() command.
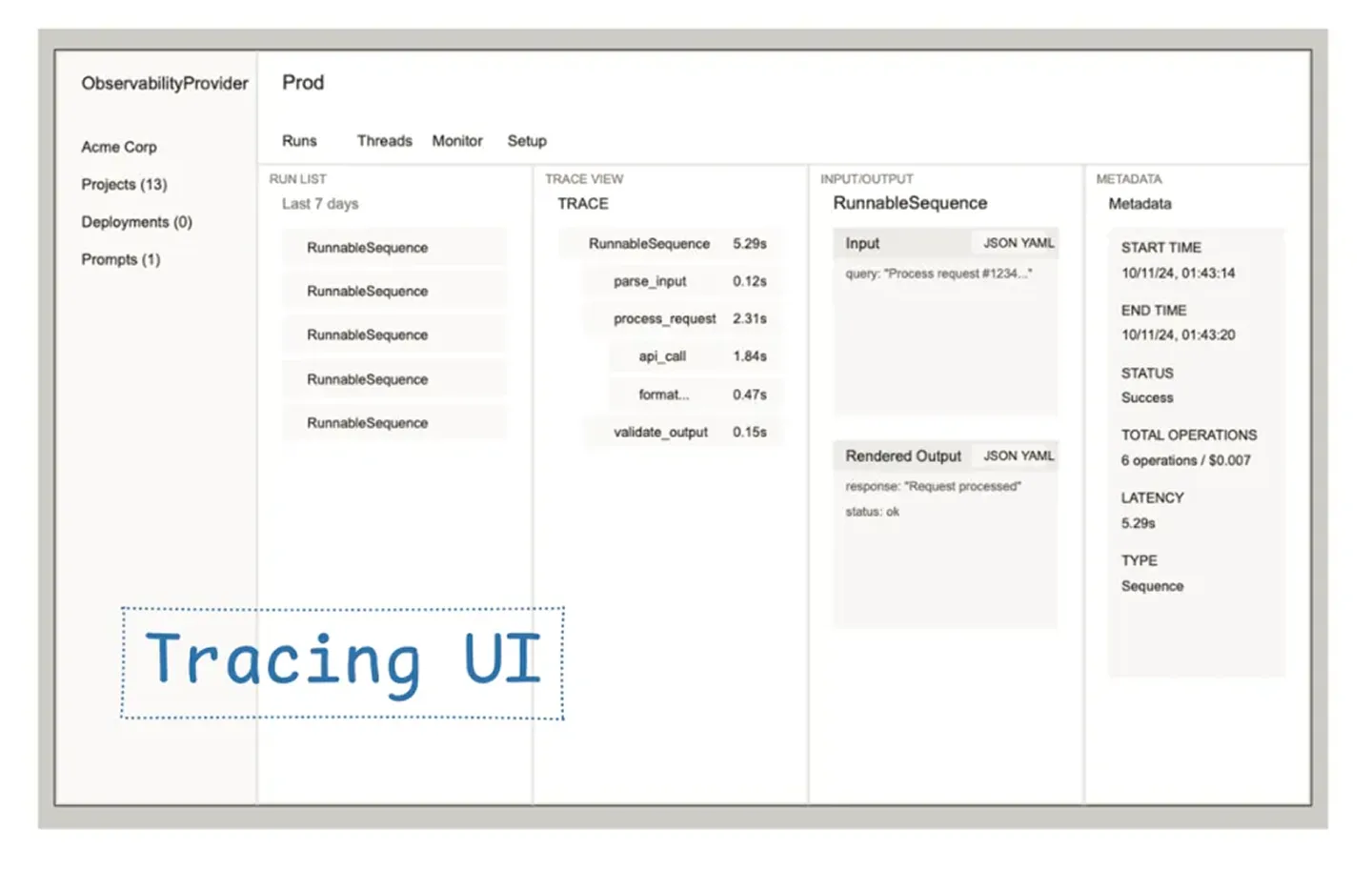
It’s helpful to compose steps in such a way that the input/output at each step is meaningful in some way, since you’ll be able to see it in your tracing
workflows need to pause execution while waiting for a third-party (like a human-in-the-loop) to provide input.
So to design a good user experience for your agent, make sure your workflows and agents stream intermediate step completion (Mastra has .watch() for this), then present these to the user in a way that maximizes snappines
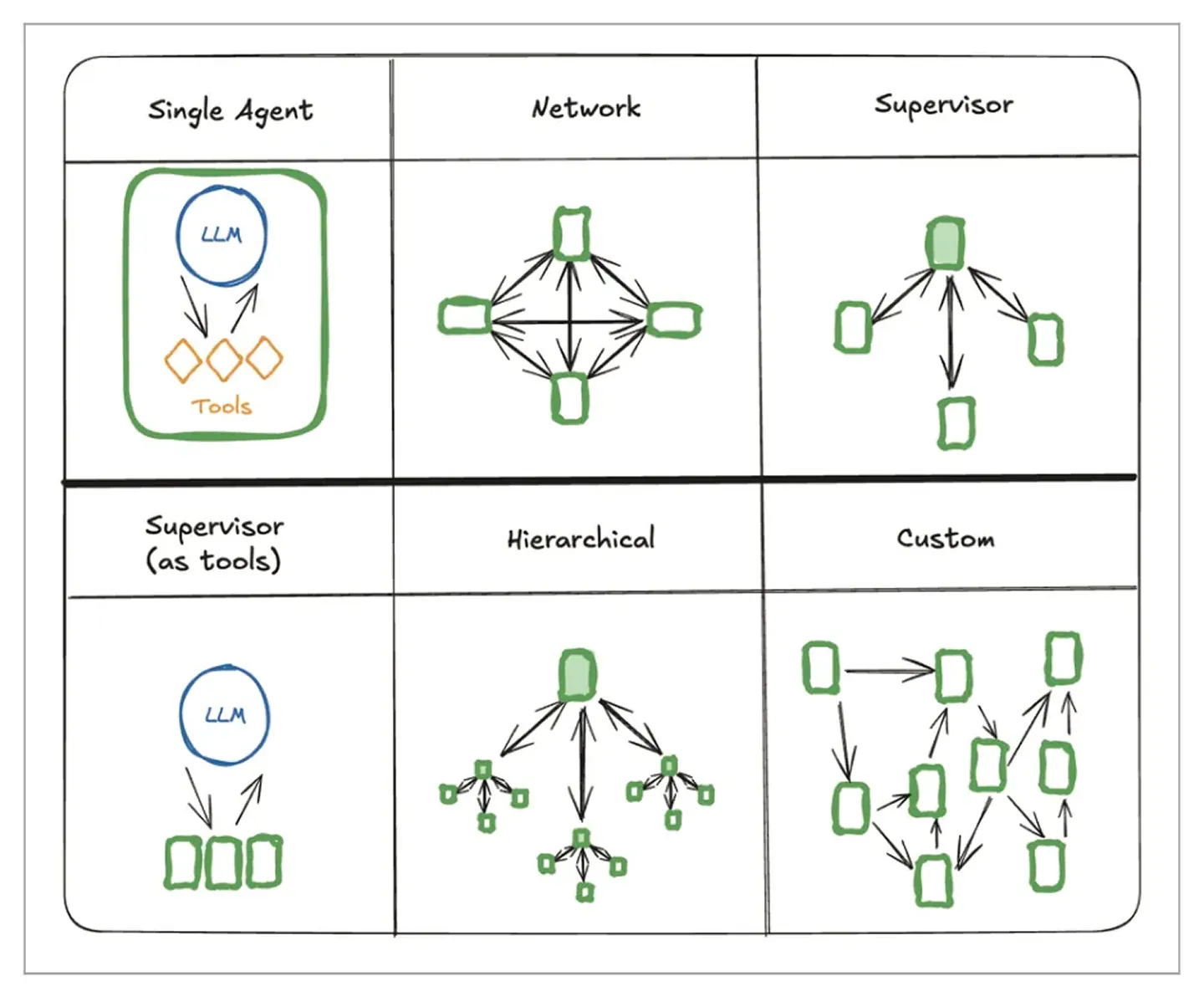
Back in the “early” days we separated the agents in: LLM + tool call + prompt. Keeping them very specific, which was closer to workflows primitive, on which we built for quite a while.
These days, as SOTA models improved across several dimensions(tool calling, context recall, negative instruction following, etc.)we give the agent more autonomy and more tools, and it can choose which tools to use at which time and deliver the answer. That’s one of our more recent learnings.
Next learning is about chaining. Sometimes you want to fetch data from a remote source before you feed it into the LLM. I think this is extremely relevant in our case as we have a lot of external data, either from SQL or GaQL or GraphQL. We have multiple tool calls that need to query the data, either through an API or SQL syntax and return the results. That’s another important piece of the workflow. We almost always have a data retrieval step.
In terms of composing these steps, we have highly specific knowledge related to advertising where a lot of metadata needs to be added into the context window in order for the query to be correct. For example when you run a natural language prompt to query you need the relevant data for the model to “understand” the question. By default — and using just model knowledge the results will be either wrong or useless. Sometimes you also need to “augment” the answer after retrieval where semantic data is added back into the pure tabular dataset we got back in the previous step.
Given all these steps the whole “agentic flow” can take even a couple of minutes. Users on the other hand want to see progress, not wait in silence. So we added partial responses or visible “thinking” steps which improved trust and usability.
Lastly — in terms of human in the loop, we don’t yet perform “real world” actions (against campaigns for example) but we can, for example, ask questions from the human to better specify the query, guide/approve for next actions, or just to clarify certain parts of the workflow/plan. And that’s another important part of how we build agents. There is a thin line though between given the agent autonomy (run with best guess) and hand-holding (asking questions at each step)
The implementation is similar to a geospatial query searching latitude/longitude, except the search goes over 1536 dimensions instead of two.
Reranking: Optionally, after querying, you can use a reranker. Reranking is a more computationally expensive way of searching the dataset.\
In practice, the most important thing is to prevent infra sprawl (yet another service to maintain).
If you’re already using Postgres for your app backend, pgvector is a great choice. If you’re spinning up a new project, Pinecone is a default choice with a nice UI. If your cloud provider has a managed vector DB service, use that.
Upsert operations allow you to insert or update vectors and their associated metadata in your vector store.
Hybrid Queries with Metadata. Hybrid queries combine vector similarity search with traditional metadata filtering. This allows you to narrow down results based on both semantic similarity and structured metadata fields like dates, categories, or custom attributes.
(use) graph databases to model complex relationships.
We’ve learned some lessons here also — around keywords, and similarity search vs relevancy and reranking. We’re light users of these techniques — but if you have a large textual/hybrid dataset: think tens of thousands of rows with multiple columns — it comes in handy to know what is possible and for which use cases.
In general semantic recall and RAG is a rather complex topic. In Berlin we found that there are both middleware (Needle) or infra (Weaviate) vendors that usually are eager to help; Easy to meet at meetups or other communities. For advertising specifically we looked at natural language queries (“naive RAG) and agentic RAG (multiple loops, query rewriting) as well as reranking (for relevancy), or a combination of these.
We’ve of course first tried to “fill” the context; But you easily get to context rot* or “noisy” context — “confusing” the LLM. Most generic / horizontal chatbots rely on the larger context windows but with vertical agents you can actually put checks and balances in place and make sure you get the desired output. Our tooling here stands from Qdrant for VectorDB, Cohere for reranking, OpenAI for embeddings but we’ve also tried off the shelf tools like Needle or Llamaindex.
One newer development to note is also Skills* in Claude which seems a promising tool in the toolbox (more on that at some other point).
different system prompts, and access to different tools.
Each of these workflows can then be passed along as tools to the agent(s).
(And in fact the code writing agent is two different agents, a reviewer and writer that work together.)
These are inverse examples to one another, which brings us, again, to an important takeaway: all the primitives can be rearranged in the way you want, custom to the control flow you want.
As I mentioned previously we now give the agent more autonomy and more tools, and it can choose which tools to use at which time in order to deliver the task. This has been mainly enabled by reasoning models and it’s one of our more recent learnings; Think of it as Claude Code vs n8n workflows. We did use chain of thought before (“think of the solution step by step”) — it worked to a certain extent but we see much better results with the latest SOTA models — which now also leverage subagents* (specialized agents, with limited context/tools — focused on subtasks)
Theinterface interchangeability is yet another interesting primitive in regards to agents.For example HYPD can be made available as an API and wrapped in as an MCP (Model Context Protocol). We actually used quite few MCPs under the hood for testing (for GAQL, GraphQL and quite a few others).
The way we think about it currently is that it’s fluid and it should be made available where the user workflow happens (so if it needs to be in in the Intercom chatbot or available in n8n for different workflows — or even orchestrating ourselves other MCPs — dependent on customer needs, long term plans and so on. Different providers already answer this question differently. But we believe in inter-operability; The A2A standard for Google fits this specific purpose and the AdCP (Ad Context Protocol) supports both.
Prompt engineering evals explore how different instructions, formats, or phrasings of user queries impact an agent’s performance. They look at both the sensitivity of the agent to prompt variations (whether small changes produce large differences in results) and the robustness to adversarial or ambiguous inputs.
Many correctness aspects (e.g., subtle domain knowledge, or an unusual user request) can’t be fully captured by rigid assertions, but human eyes catch these nuances.
One of the most important dataset is translating your customers’ needs expressed into natural language (if that is the input) — but also what the desired outputs of those needs are so you can test against!.
In our case we’re building conversational agents — it’s basically queries and answers — but as we focus on structured data — data accuracy is paramount so we need intermediate steps evals (for tool calling or individual agents) — which for example most vendors don’t offer out of the box (Langfuse offers it as code, but not in the UI)
Once again — the easiest way is to start manually (questions/answers) and then automate as scale and number of use cases grow. Once in production and at scale we are now using actual user queries — both for good and bad examples as evals.
Agent Chat Interface: Test conversations with your agents in the browser, seeing how they respond to different inputs and use their configured tools. Workflow Visualizer: Seeing step-by step workflow execution and being able to suspend/resume/replay Agent/workflow endpoints: Being able to curl agents and workflows on localhost (this also enables using eg Postman)
Tool Playground: Testing any tools and being able to verify inputs / outputs without needing to invoke them through an agent. Tracing & Evals: See inputs and outputs of each step of agent and workflow execution, as well as eval metrics as you iterate on code.
But from a developer perspective: the ideal runtime for agents and workflows is serverless, and autoscales based on demand, with state maintained across agent invocations by storage built into the platform.
There’s a large number of observability vendors, both older backend and AI-specific ones, but the UI patterns converge:
In general software development best practices are not that different from building agents; You’ll need a local environment; You might also want a staging environment to QA things properly.
What is different is that indeed we are coding with agents (Claude Code, Amp, Devin) and using MCPs to accelerate learnings, development, fix bugs or review code.
In terms of tooling we found that testing tools (MCPs) with Claude before development helps us understand the edges better and spec the tickets accordingly.
Another testing platform we’ve used extensively is n8n — you can get A LOT done before getting to development. Other than that — having proper access to the database (for message history, tool calls) is sometimes helpful when traces are not enough. Some of these features (message history, tool calling, and even evals) — can be abstracted away behind for example Responses API from OpenAI or Skills behind Claude API / Agents SDK. We haven’t picked a side yet :) — and for now we’d like to keep the optionality for OSS models also.
Last note here — we refactored the platform a couple of times so far and every time we were both faster and having a more robust product at the end of it. Now we have made some bets which hopefully will keep us on this trajectory for at least a while (a year+ or more!)
There are a couple more points that we’ve either stumbled upon in our practice or we think will be relevant in the future or maybe even in the present for other builders.
For example we see a lot of “horizontal” agents with tens of standard integrations (from Gmail, to Dropbox, to MSuite and so on) but only a few that have vertical specific integrations (for Marketing/Advertising for example).
And because these use cases are not yet mainstream some of the solutions (see Google auth for MCPs) might still use “traditional” connectors rather than agentic ones.
The other piece is hype vs reality. We did talk about MVPs, and POCs vs production. And the gap is the biggest there. On one side we see large projects deployed on Langgraph (Klarna, Vodafone, etc.) but at the same time we also see a flood of many open source components / repos — with thousands of weekly downloads — that are often not updated for months and will probably get abandoned?
Sometimes a simple workflow in a no-code tool is enough; And building an agent needs to be rooted in real business use cases — and that applies for open source repos as well. There are subtle differences between agents and workflows and these days they can work in concert.
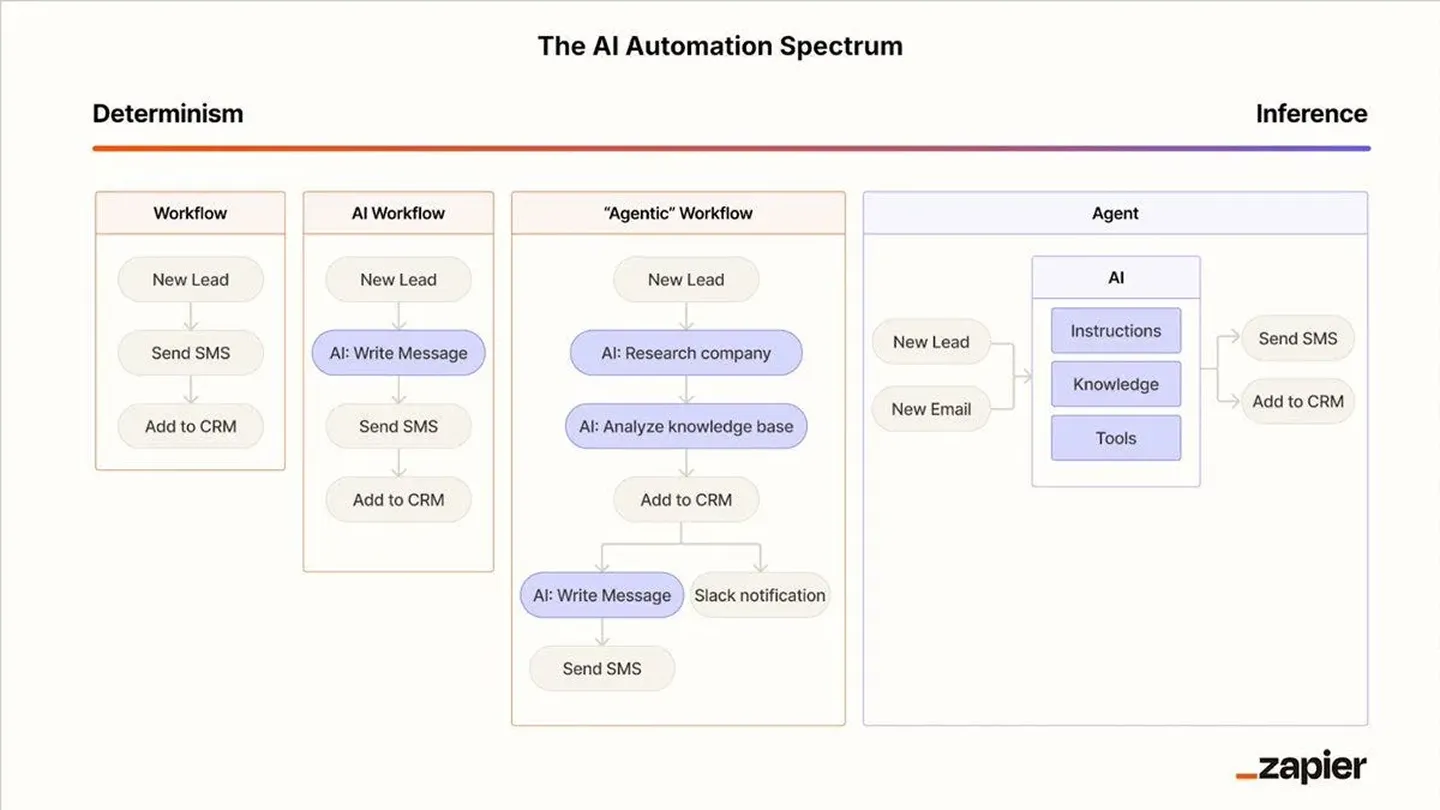
Outside of the hype, the industry does move at an accelerated pace. We went from prompt engineering to context engineering and from “manual” tool use and workflows to MCPs, skills and deep agents. More primitives and best practices are following across each of these as more companies take AI agents to production (especially lessons from Claude Code team!*). We have now long running agents, agents built via chat, ambient / proactive agents plus already advanced methods for context engineering (like DSPy, handoffs, etc.) and tool use (Code Mode). As these are relatively new developments we’ll share what we learn as we experiment with bringing the relevant ones into our production agents.
Lastly I think it’s helpful to identify the components of the stack — and which parts youneed to build, customize or buy; At the high level there are overlaps between thefoundation layer, middleware and application layer, but as you go deeper, the demarcation lines become clearer (in terms of actual value add and solving specific vs generic problems). Going through this process also helps narrow your scope as well also picking the right tool based on the companies focus/direction.
This article was originally posted on Medium



%201.png)