Notizen zum Mastra-Buch — Prompts, RAG, Evals — aus dem Bau von HYPD.
Einleitung
Ich habe Principles of building AI Agents vor ein paar Monaten gelesen, das gedruckte Exemplar aber erst vor wenigen Wochen bekommen. Ich trage es seitdem oft mit mir herum — vor allem, um es besser einordnen zu können, nachdem andere ihre Sicht schon geteilt haben.
Was mich besonders interessiert hat: Primitive als Grundlage für den Bau von Agenten. Als wir 2024 mit dem Bau anfingen, gab es kaum Material dazu. Mit IndieGrow haben wir sogar ein „Deep Research"-Tool gebaut, bevor es „cool" war oder es viel Literatur dazu gab — heute hat fast jedes Lab und jede Middleware-Company eine Variante davon.
Wie auch immer: ich empfehle das Buch sehr. Ursprünglich wollte ich nur Lesenotizen teilen, hatte aber bereits ein paar Seiten Highlights — daraus wurde ein ordentlicher Write-up inklusive unserer bisherigen Erfahrungen.
Das Buch hat kein Inhaltsverzeichnis, ein kurzes wäre nützlich:
- Teil I — Prompts
- Teil II — Agenten bauen
- Teil III — Workflows
- Teil IV — RAG
- Teil V — Multi-Agent-Systeme
- Teil VI — Evals
- Teil VII — Dev & Deployment
Und ich habe ergänzt:
- einen kurzen Outro mit ein paar aufkommenden Primitiven/Best Practices, die wir gesehen haben
- ein paar weitere Lesezeichen, die ich relevant fand (Further Reading)
Kapitel I — Prompts (und Context Engineering)
Zero-shot: Der „YOLO"-Ansatz. Frage stellen und auf das Beste hoffen. Single-shot: Frage stellen, dann ein Beispiel (Input + Output) zur Steuerung mitliefern. Few-shot: Mehrere Beispiele für präzisere Kontrolle über den Output. Wir haben in Mastras lokale Dev-Umgebung deshalb ein Prompt-CMS eingebaut. GROSSBUCHSTABEN können bestimmten Wörtern Gewicht verleihen. XML-artige Strukturen helfen Modellen, Anweisungen präziser zu folgen. Claude & GPT-4 reagieren besser auf strukturierte Prompts (z. B. Task, Context, Constraints).
Notizen
Das haben wir aus erster Hand erlebt. Als wir bei HYPD anfingen, haben wir die Modelle mit „offline" Datensätzen sowohl gegen ChatGPT als auch Claude getestet — wir wollten sehen, wie weit man reine LLM-Performance pushen kann, bevor man Prompts ergänzt. Wir haben früh gemerkt, dass Prompt-Versionierung und -Struktur der Schlüssel zum gewünschten Output sind. Es ist das fundamentalste Primitive, und ehrlich gesagt habe ich nicht verstanden, wie tief das geht, bis ich Andrej Karpathy im Dwarkesh-Podcast* gehört habe.
Auch heute geht ein großer Teil unserer Zeit ins Auseinandernehmen von Prompts — Struktur, Wörter, kleine Unterschiede testen und sehen, wie sie Outputs verändern.
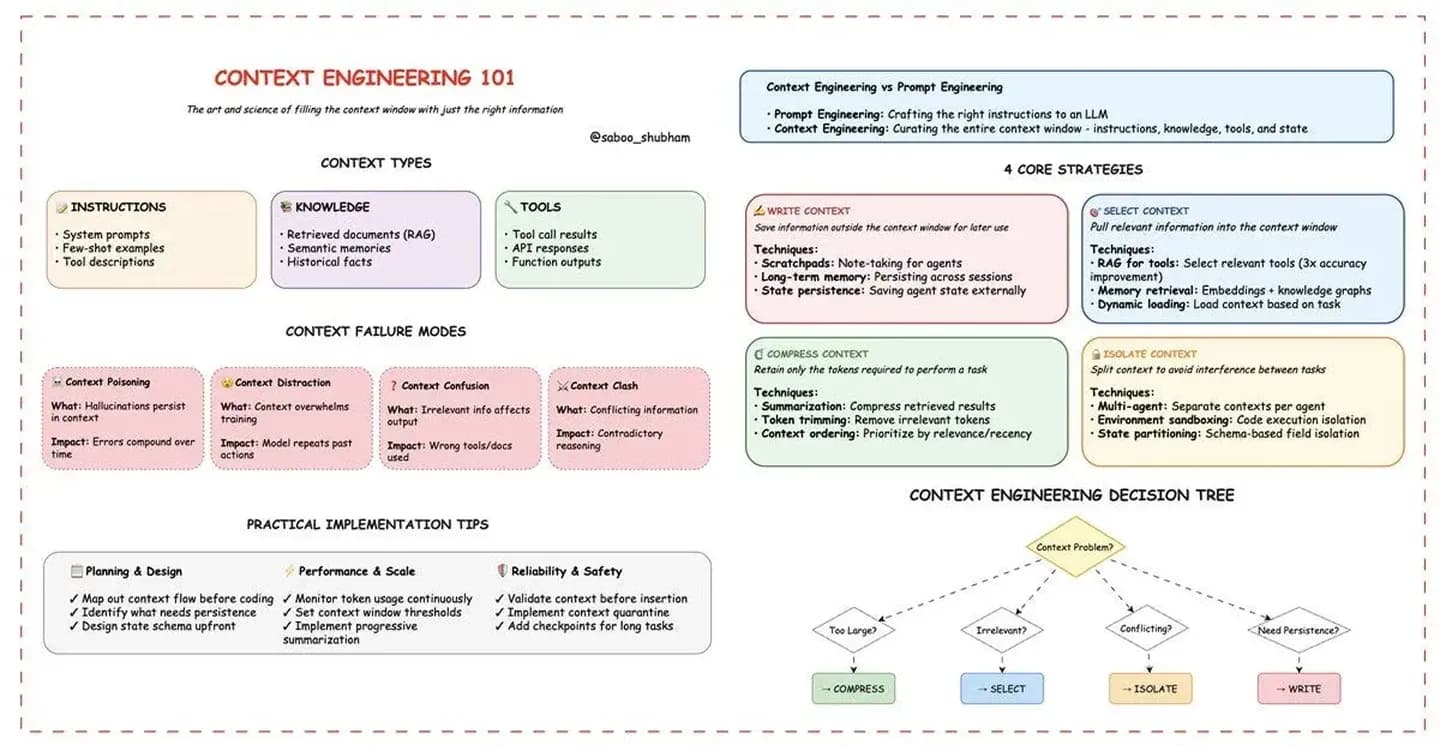
Interessanter ist, dass sich diese „Disziplin" inzwischen zu Context Engineering entwickelt hat — sie umfasst zusätzlich Tool-Beschreibungen, Beispiele, Message History, Memory, RAG und weitere Inhalte/Kontextbausteine, die dem Modell zur Verfügung stehen.
In der Praxis, weil LLMs „stateless" sind, baust du entweder den Kontext rund um den Agenten selbst oder nutzt Frameworks (wie Mastra oder Langgraph), die das übernehmen.
Kapitel II — Einen Agenten bauen
Die meisten Modelle unterstützen „Structured Output", um das zu ermöglichen. Verwende semantische Namen, die zur Funktion des Tools passen (z. B. multiplyNumbers statt doStuff). semanticRecall zeigt an, dass wir RAG nutzen (später mehr), um vergangene Konversationen zu durchsuchen. topK ist die Anzahl der zu holenden Nachrichten. messageRange ist der Bereich um den Treffer, der einbezogen wird.
Notizen
Bei Structured Outputs war es eine interessante Entwicklung („deterministisches" JSON oder ähnliches Format als Rückgabe). Wir nutzen das in mehreren Agenten — vom Intent-Classifier über den SQL-Generator bis zur Generierung von Fehlermeldungen. OpenAI war Vorreiter und hat es ziemlich verlässlich gemacht. Für Agent-„Actions" finde ich das besonders nützlich.
Bevor wir zu Tool-Use kommen: Die aktuell verbreitete Definition* lautet:
ein LLM plus Tool(s) mit einem Ziel, in einer Schleife laufend, um die Aufgabe zu erfüllen
Wir nutzen verschiedene Tools, etwa SQL/GAQL-Generierung oder das Rendern von Charts. Anfangs waren Tools direkt einzelnen Agenten zugeordnet, und wir tracen, wann sie genutzt werden.
Zu semantischen Namen — das spricht für sich. Ob nötig sei dahingestellt, aber semantische Namen sind generell leichter für Modelle, leichter für Menschen zu lesen oder für DeepWiki* zum Verknüpfen.
RAG (Retrieval Augmented Generation) ist ein etwas komplexeres Thema und kommt später. Kurz gesagt: Es passt in den breiteren Context-Engineering-Primitiv mit all seinen Komponenten. RAG kann an vielen Stellen passieren. Für Nachrichten und Nachrichtenhistorie geben wir z. B. den vollen Kontext mit. Für Memory/Personalisierung hingegen ergibt es Sinn, nicht alles, sondern nur die relevanten Teile zu laden.
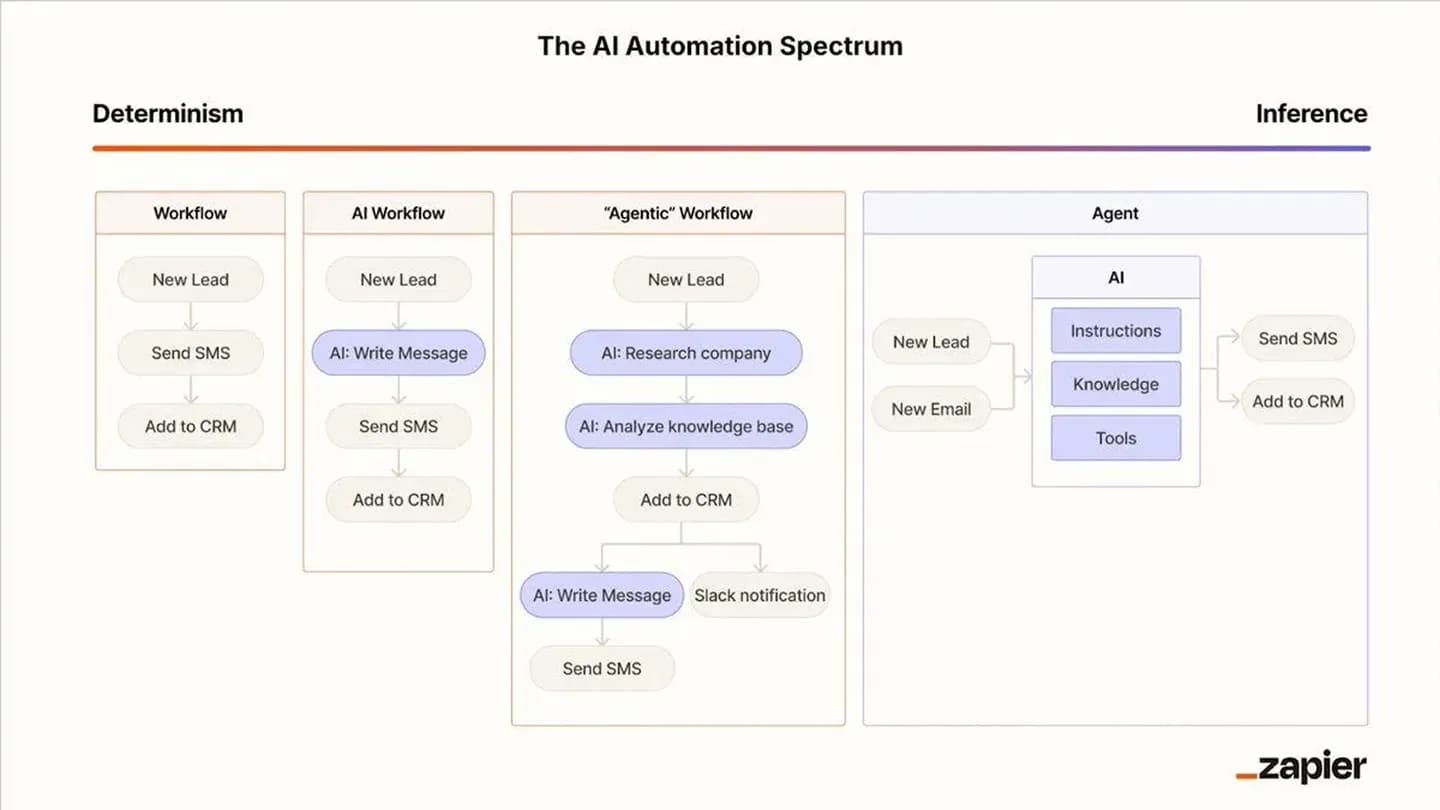
Kapitel III — Graphbasierte Workflows
Du könntest einen einzigen LLM-Call 12 Symptome prüfen lassen. Aber das ist viel verlangt. Besser: 12 parallele LLM-Calls, jeder prüft ein Symptom. Manchmal willst du Daten von einer Remote-Quelle holen, bevor du sie ins LLM gibst, oder die Ausgabe eines LLM-Calls in den nächsten. In Mastra kettest du mit dem .then()-Befehl. Es ist hilfreich, Schritte so zu komponieren, dass Input/Output jedes Schritts aussagekräftig ist, weil du das im Tracing sehen kannst. Workflows müssen die Ausführung pausieren, während sie auf einen Drittparty-Input warten (z. B. Human-in-the-loop). Für eine gute User Experience sollten dein Workflow und deine Agenten Zwischenschritte streamen (Mastra hat .watch() dafür) und sie dem Nutzer so präsentieren, dass es snappy wirkt.
Notizen
In den „frühen" Tagen haben wir Agenten getrennt in: LLM + Tool Call + Prompt. Sehr spezifisch — näher am Workflow-Primitiv, auf dem wir lange aufgebaut haben.
Heute, mit verbesserten SOTA-Modellen (Tool Calling, Context Recall, Negative-Instruction-Following etc.), geben wir Agenten mehr Autonomie und mehr Tools. Sie wählen selbst, welches Tool sie wann nutzen, und liefern die Antwort. Das ist eines unserer jüngeren Learnings.
Nächstes Learning: Verkettung. Manchmal willst du Daten aus einer Remote-Quelle holen, bevor du sie ins LLM speist. In unserem Fall extrem relevant — wir haben viele externe Daten, sei es aus SQL, GAQL oder GraphQL. Wir haben mehrere Tool Calls, die Daten per API oder SQL anfragen und Ergebnisse zurückgeben. Das ist ein wichtiger Workflow-Baustein. Wir haben fast immer einen Daten-Retrieval-Schritt.
Beim Komponieren dieser Schritte haben wir sehr spezifisches Werbe-Wissen: Eine Menge Metadaten muss ins Context-Window, damit die Query korrekt ist. Beispiel: Natural-Language-Query → das Modell braucht relevante Daten, um die Frage zu „verstehen". Mit reinem Modellwissen sind die Ergebnisse meist falsch oder nutzlos. Manchmal musst du die Antwort nach dem Retrieval auch „augmentieren": semantische Daten kommen zurück in das tabellarische Ergebnis aus dem vorigen Schritt.
Mit all diesen Schritten kann der „Agenten-Flow" mehrere Minuten dauern. Nutzer:innen wollen aber Fortschritt sehen, nicht still warten. Also haben wir Teilausgaben und sichtbare „Thinking"-Schritte ergänzt — das hat Vertrauen und Usability verbessert.
Zuletzt — Human-in-the-loop. Wir führen noch keine „echten" Aktionen (z. B. an Kampagnen) aus, können aber Rückfragen stellen, um die Query zu schärfen, nächste Schritte freigeben zu lassen oder Teile des Workflows/Plans zu klären. Wichtiger Aspekt, wie wir Agenten bauen. Es ist ein schmaler Grat zwischen Agent-Autonomie (mit bestem Guess loslegen) und Hand-Holding (an jedem Schritt nachfragen).
Kapitel IV — RAG
Die Implementierung ähnelt einer Geo-Query (Latitude/Longitude), nur dass die Suche über 1536 Dimensionen statt zwei läuft. Reranking: Optional kannst du nach der Suche einen Reranker einsetzen. Reranking ist rechenintensiver. In der Praxis: vermeide Infra-Wildwuchs (noch ein weiterer Service). Wenn du Postgres als Backend nutzt, ist pgvector eine gute Wahl. Bei neuen Projekten ist Pinecone Standard mit hübschem UI. Hat dein Cloud-Provider einen Managed-Vector-DB-Service: nutze ihn. Upsert-Operationen erlauben Insert/Update von Vektoren + Metadaten im Vector Store. Hybrid Queries mit Metadaten: Kombiniert Vector-Similarity-Suche mit klassischem Metadaten-Filter. Damit kannst du Ergebnisse über semantische Nähe plus strukturierte Felder (Daten, Kategorien, eigene Attribute) eingrenzen. Nutze Graph-Datenbanken für komplexe Beziehungen.
Notizen
Auch hier haben wir Learnings — rund um Keywords, Similarity-Suche vs. Relevanz und Reranking. Wir sind „Light User" dieser Techniken — aber bei großen Text-/Hybrid-Datensätzen (zehntausende Zeilen, viele Spalten) ist es nützlich zu wissen, was möglich ist und wann es passt.
Semantic Recall und RAG sind ein recht komplexes Thema. In Berlin haben wir Middleware- (Needle) wie Infra-Anbieter (Weaviate) gefunden, die gern helfen — leicht zu treffen auf Meetups. Für Werbung haben wir uns sowohl naive RAG (Natural-Language-Query) als auch agentisches RAG (mehrere Loops, Query-Rewriting), Reranking (für Relevanz) und Kombinationen davon angesehen.
Wir haben natürlich auch versucht, den Kontext „vollzustopfen". Aber man landet schnell bei Context Rot* oder „noisy" Kontext — das LLM wird konfus. Generische / horizontale Chatbots verlassen sich auf größere Context-Windows; bei vertikalen Agenten kannst du Checks & Balances einbauen, damit der gewünschte Output kommt. Unser Stack hier: Qdrant für VectorDB, Cohere für Reranking, OpenAI für Embeddings — daneben Tests mit Needle und LlamaIndex.
Eine neuere Entwicklung: Skills* in Claude — wirkt wie ein vielversprechendes Werkzeug im Werkzeugkasten (mehr dazu ein anderes Mal).
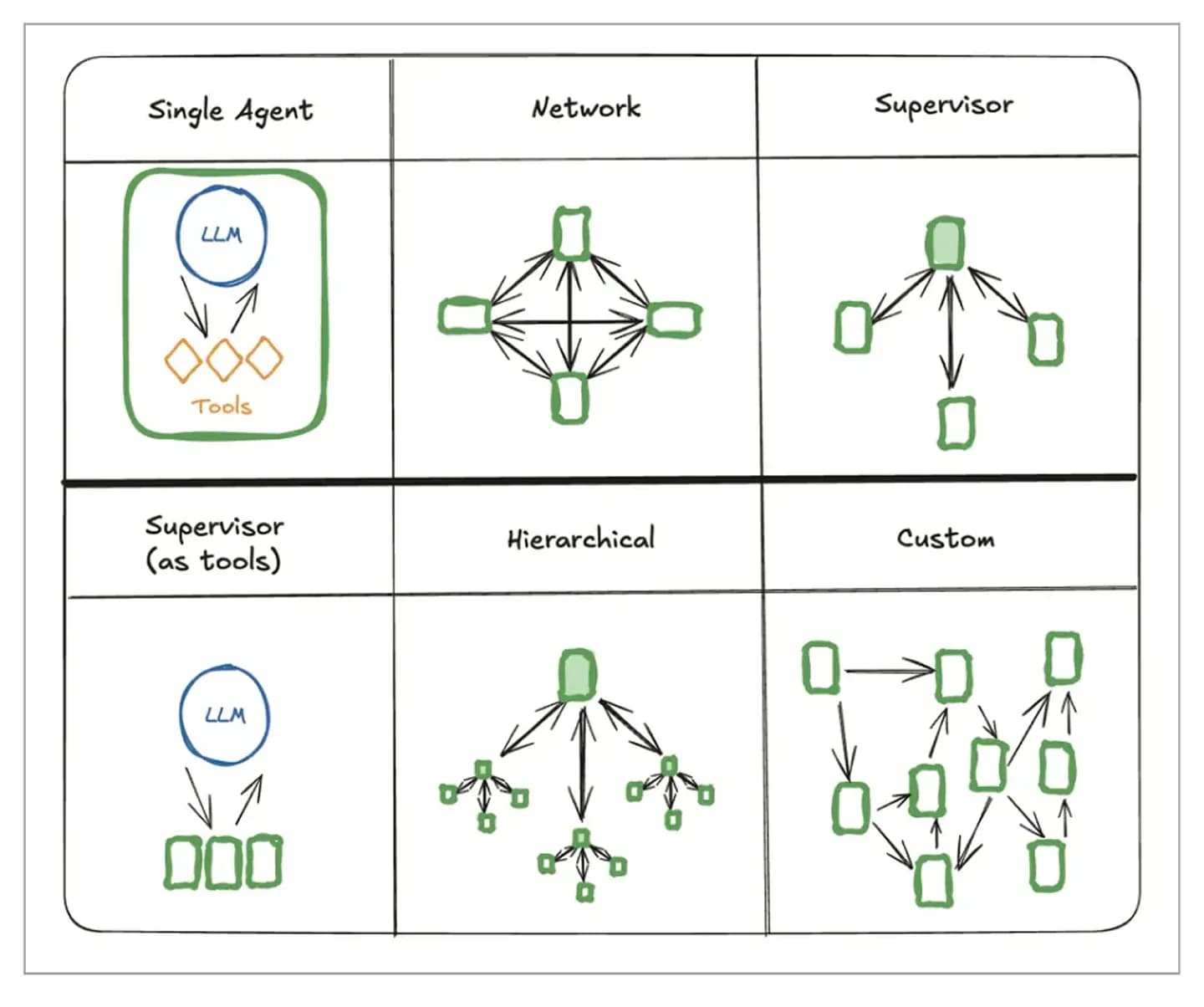
Kapitel V — Multi-Agent-System
Unterschiedliche System-Prompts und Zugriff auf unterschiedliche Tools. Jeder dieser Workflows kann als Tool an den/die Agenten weitergereicht werden. (Und der Code-Schreib-Agent ist tatsächlich zwei Agenten: Reviewer und Writer, die zusammenarbeiten.) Das sind inverse Beispiele zueinander — und es führt erneut zur wichtigen Erkenntnis: alle Primitiven lassen sich in der gewünschten Weise neu arrangieren, passend zum Control-Flow.
Notizen
Wie gesagt: wir geben dem Agenten mehr Autonomie und mehr Tools, und er wählt selbst, welches Tool wann genutzt wird, um die Aufgabe zu lösen. Möglich wurde das vor allem durch Reasoning-Modelle. Stell es dir vor wie Claude Code vs. n8n-Workflows. Wir haben vorher mit Chain-of-Thought gearbeitet („denk Schritt für Schritt nach"), das hat bis zu einem Punkt funktioniert — aber wir sehen mit den neuesten SOTA-Modellen deutlich bessere Ergebnisse, die zudem Subagenten* (spezialisierte Agenten mit eingeschränktem Kontext/Tools, fokussiert auf Teilaufgaben) nutzen.
Interface-Interchangeability ist ein weiteres spannendes Agenten-Primitiv. HYPD kann z. B. als API bereitstehen und als MCP (Model Context Protocol) gewrappt sein. Wir haben für Tests etliche MCPs unter der Haube genutzt (GAQL, GraphQL u. a.).
Unsere Sicht: Es ist fließend — und sollte dort verfügbar sein, wo der User-Workflow stattfindet (Intercom-Chatbot, n8n, oder selbst andere MCPs orchestrieren — abhängig von Kundenbedarf und langfristiger Roadmap). Verschiedene Anbieter beantworten das unterschiedlich; wir setzen auf Interoperabilität: Googles A2A-Standard passt dafür, und AdCP (Ad Context Protocol) unterstützt beides.
Kapitel VI — Evals
Prompt-Engineering-Evals prüfen, wie unterschiedliche Anweisungen, Formate oder Formulierungen die Performance eines Agenten beeinflussen. Sowohl Sensitivität gegenüber Prompt-Varianten (führen kleine Änderungen zu großen Unterschieden?) als auch Robustheit gegenüber adversarialen/uneindeutigen Inputs. Viele Aspekte von Korrektheit (z. B. feines Domänenwissen, ungewöhnliche User-Requests) lassen sich nicht voll über rigide Assertions abbilden, aber menschliches Auge erkennt diese Nuancen.
Notizen
Einer der wichtigsten Datensätze: die Bedürfnisse deiner Kund:innen in natürliche Sprache übersetzen (falls das der Input ist) — und festhalten, wie die gewünschten Outputs aussehen, gegen die du testen willst.
Wir bauen Conversational Agents — im Kern Fragen und Antworten — aber da wir uns auf strukturierte Daten konzentrieren, ist Datengenauigkeit zentral. Wir brauchen Zwischenschritt-Evals (für Tool Calls oder einzelne Agenten) — das bieten die meisten Vendor nicht out-of-the-box (Langfuse z. B. als Code, nicht im UI).
Wie so oft: manuell starten (Fragen/Antworten) und automatisieren, wenn Skala und Use Cases wachsen. In Produktion und im Maßstab nutzen wir reale Nutzer-Queries — gute wie schlechte — als Evals.
Kapitel VII — Entwicklung & Deployment
Agent-Chat-Interface: Konversationen mit deinen Agenten im Browser testen, sehen, wie sie auf unterschiedliche Inputs reagieren und ihre konfigurierten Tools verwenden. Workflow-Visualizer: Schritt-für-Schritt-Ausführung sehen und pausieren/fortsetzen/replayen können. Agent-/Workflow-Endpunkte: Agenten/Workflows lokal per curl ansprechen (auch nutzbar mit z. B. Postman). Tool Playground: Tools testen, Inputs/Outputs prüfen, ohne sie über einen Agenten aufrufen zu müssen. Tracing & Evals: Inputs und Outputs jedes Schritts der Ausführung sehen, plus Eval-Metriken beim Iterieren. Aus Entwickler-Sicht: die ideale Runtime für Agenten/Workflows ist serverless, skaliert nach Bedarf, mit Plattform-State über Agent-Invocations hinweg. Es gibt viele Observability-Anbieter (alte Backend und KI-spezifisch), aber die UI-Patterns konvergieren:
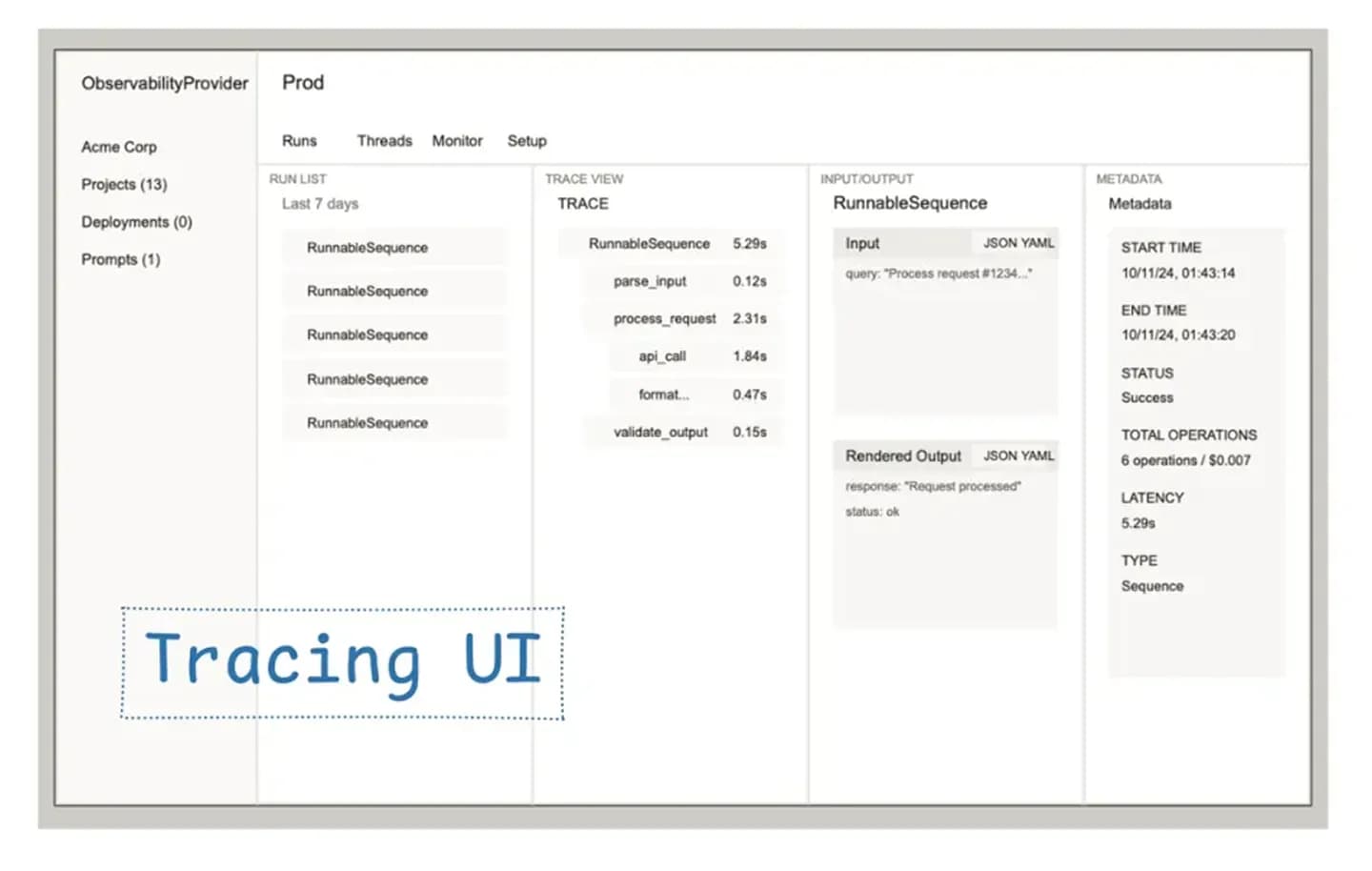
Notizen
Generell sind Software-Best-Practices für Agenten kaum anders; du brauchst eine lokale Umgebung, vermutlich auch Staging fürs QA.
Anders ist, dass wir mittlerweile mit Agenten coden (Claude Code, Amp, Devin) und MCPs nutzen, um Learnings, Entwicklung, Bugfixes und Reviews zu beschleunigen.
Beim Tooling haben wir gemerkt: Tools (MCPs) mit Claude zu testen, bevor wir entwickeln, hilft, Grenzen besser zu verstehen und Tickets entsprechend zu spezifizieren.
Eine weitere Plattform, die wir extensiv genutzt haben, ist n8n — du kannst SEHR viel erledigen, bevor du in die Entwicklung gehst. Außerdem ist ein vernünftiger DB-Zugriff (für Message History, Tool Calls) hilfreich, wenn Traces nicht reichen. Manches (Message History, Tool Calling, sogar Evals) kannst du wegabstrahieren — z. B. mit OpenAIs Responses API oder Skills hinter der Claude API / Agents SDK. Wir haben uns nicht festgelegt :) — wollen die Optionalität auch für OSS-Modelle behalten.
Eine letzte Notiz: Wir haben die Plattform mehrfach refactored und waren jedes Mal schneller und robuster danach. Inzwischen haben wir ein paar Bets gemacht, die uns hoffentlich eine Weile (ein Jahr+) auf Kurs halten.
Outro
Ein paar Punkte mehr, auf die wir entweder gestoßen sind oder die in Zukunft (oder schon heute) für andere Bauer:innen relevant sein dürften.
Beispiel: Wir sehen viele „horizontale" Agenten mit Dutzenden Standard-Integrationen (Gmail, Dropbox, MSuite usw.), aber nur wenige mit vertikalen Integrationen (z. B. Marketing/Werbung).
Und weil diese Use Cases noch nicht Mainstream sind, nutzen einige Lösungen (z. B. Google-Auth für MCPs) noch „klassische" Connectoren statt agentischer.
Anderer Punkt: Hype vs. Realität. Wir haben über MVPs, POCs vs. Produktion gesprochen — und die Lücke ist dort am größten. Auf einer Seite große Projekte auf Langgraph (Klarna, Vodafone etc.), gleichzeitig eine Flut von OSS-Komponenten mit tausenden wöchentlichen Downloads, die monatelang nicht gepflegt werden und vermutlich liegen bleiben.
Manchmal reicht ein einfacher Workflow im No-Code-Tool; und Agenten bauen sollte in echten Business-Use-Cases verankert sein — das gilt auch für OSS-Repos. Zwischen Agenten und Workflows gibt es feine Unterschiede, sie können heute auch im Zusammenspiel laufen.
Jenseits des Hypes bewegt sich die Industrie in beschleunigtem Tempo. Wir sind von Prompt Engineering zu Context Engineering gekommen, von „manueller" Tool-Nutzung und Workflows zu MCPs, Skills und Deep Agents. Mit jedem Schritt etablieren sich neue Primitive und Best Practices (besonders Lessons aus dem Claude-Code-Team*!). Wir haben jetzt lang laufende Agenten, im Chat gebaute Agenten, Ambient/Proaktive Agenten und schon fortgeschrittene Methoden im Context Engineering (DSPy, Handoffs etc.) und Tool Use (Code Mode). Da das alles relativ neu ist, teilen wir, was wir lernen, während wir Relevantes in unsere Produktionsagenten bringen.
Zum Schluss: Es hilft, die Komponenten des Stacks zu identifizieren — und zu klären, welche Teile man bauen, anpassen oder kaufen sollte. High-level gibt es Überlappungen zwischen Foundation-Layer, Middleware und Application-Layer, aber je tiefer es geht, desto klarer werden die Demarkationslinien (in Bezug auf tatsächlichen Mehrwert und spezifisches vs. generisches Problem-Solving). Der Prozess hilft, den Fokus zu schärfen und das passende Tool zur Ausrichtung der Firma zu wählen.